Our sense of time speeds up as we age. So, as we get older, we perceive time to pass faster. While this experience of time is intriguing on the face of it, science has deciphered this and attributes it to the general decline in the amount of new perceptual information absorbed as we age. In the presence of more stimuli and lots of new information as during childhood, our brains take longer to process those and the period of time feels longer. With most adults stuck in a routine, the more familiar we become with day-to-day life experiences, the faster time seems to pass. If you think you have trouble keeping up now, buckle up as the world is about to change even faster with the pace of innovation and disruption accelerating.
Consulting firm Protiviti reports that C-level executives are most concerned, rightly so as I explain below, about digital disruption and their readiness to compete against born-digital organizations. In the past centuries, industries were disrupted by those who made products smaller, faster, better or cheaper through innovations in hardware components, supply chain sourcing and manufacturing processes, superior craftsmanship and any geopolitical advantage in securing raw materials. Over the decades, innovations have predominantly shifted from hardware to software. Today, industries are being disrupted by a new force, software. In the WSJ essay in 2011, Marc Andreessen proclaimed that software is eating the world and noted how just about every industry is upended by companies which operate as a software company at the core.
I was invited to be a speaker at the DevOps and Test Automation Summit held in Dallas, Texas earlier this month (February 2019) and rest of this blog article is a transcript of my talk on the topic of “From Legacy to Modern – From Ops to DevOps.”

I’m a Director of Product Management focused on building Cloud-Native service offerings, of which DevOps is a key component. My talk was a lot focused on painting a picture on how DevOps journey could look like for an organization, rather than prescribing tools as DevOps is not an one-size-fits-all-approach and tools are to be chosen by individual teams based on their pain points, critical needs, application environment and transformational goals.
2018 – Year of Enterprise DevOps
Before we talk about the DevOps journey, let’s evaluate the extent of DevOps adoption in the market, and also why organizations embark on this journey. This could probably help you make a strong case on why you need to do DevOps at a larger scale within your organization.
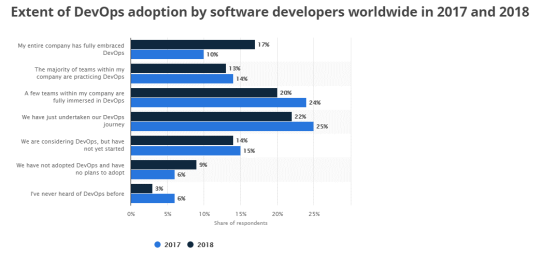
Adoption stats from Statista indicate that DevOps has gone mainstream with 50% having implemented DevOps. If we take a closer look, we see that 30% of organizations have almost fully adopted it, while 20% have atleast a few teams fully immersed in it. Given the level of adoption, analysts like Forrester have referred to 2018 as the “year of enterprise DevOps”.
Key Pillars for Digital Transformation
Why do organizations embrace DevOps? Let’s take a step back and look at the bigger picture.
No industry is immune to disruption. New software-driven products and experiences are impacting virtually every industry, with the well-known ones being Amazon in retail, Netflix in cable TV and movies, Spotify in music, Airbnb in short-term rental and Uber in ride-sharing. So, organizations across industry verticals see digital business initiatives as critical to their success.

Businesses want to develop digital infrastructure to enable easy, personalized and 24/7 access to information and data. They want to achieve more with less through improved operational efficiency and developer productivity. They want business agility to reduce time to value, and better compete with digital natives. While businesses are rapidly innovating and driving growth and competitive advantage through new technologies and practices, they’re cognizant of an increasingly complex risk landscape and want to maintain the precarious balance between protecting against cybersecurity threats and business demand for speed. To achieve this level of digital transformation and customer centricity, every business must become a software company in the App Economy, and Speed of Application Development and Delivery is the new digital business imperative.
DevOps enables Cloud-Native applications
In the previous section, we saw that Software is driving today’s innovation and disrupting entire markets. At the core of that disruption are equally new and innovative development and delivery methods for the software itself. And those principles form cloud-native. Cloud-native is the future of application development as it moves an idea into production quickly and efficiently. It goes beyond IT transformation and aims at fundamentally transforming a business. Evolving toward cloud-native application development and delivery is multidimensional, affecting culture, processes, architecture, and technology.
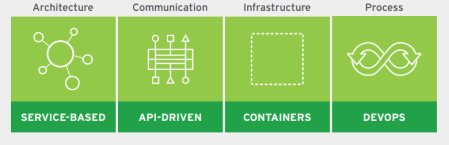
Figure: Tenets of Cloud-native application development and deployment (Source: RedHat)
A cloud-native approach is not focused on where applications are deployed, but instead on how applications are built, deployed, and managed. It is based upon four key tenets – all of which are focused on enabling small teams working on small batches of shippable software by delivering continuously – (1) Service-based architecture, (2) API-based communication, (3) container-based infrastructure, and (4) DevOps processes. Let us explore each of these tenets to understand it better.
Service-based architecture, such as microservices, advocates building modular, loosely coupled services. You have to be doing DevOps, and you have to be doing continuous delivery in order to do microservices.
To expose these services, lightweight, technology-agnostic APIs are used to reduce complexity and overhead of deployment, scalability, and maintenance. APIs also allow businesses to create new capabilities and opportunities internally, and externally via channel partners and customers.
Cloud-native applications rely on containers for a common operational model across technology environments and true application portability across different environments and infrastructure, including public, private, and hybrid. Cloud-native applications scale horizontally, adding more capacity by simply adding more application instances, often through automation within the container infrastructure.
Achieving a successful cloud-native strategy means embracing agile, high-quality app development, enabled by DevOps.
Sample Cloud-Native Maturity Matrix
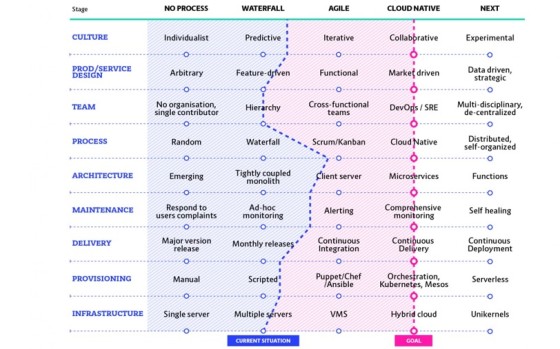
Source: https://container-solutions.com/cloud-native-maturity-matrix/
Before you initiate the cloud-native transformation, evaluate where you are today and decide on where you want to go. It is important to stay in sync on various aspects of maturity as you progress along the cloud-native scale to avoid bottlenecks. You could put together your own maturity assessment matrix. I’ve shared a sample matrix just to help get across my message. It is important to understand your current processes, and crucially your internal culture and its pivotal role in transformation, to avoid an expensive waste of time and resources through potential bottlenecks.
Agile & DevOps
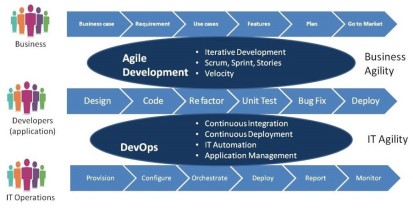
Source: http://www.effectivepmc.com/devops
I’d like to take a couple of mins to levelset on how I use Agile/DevOps and CI/CD in my conversation. Each of these are distinct and important. When all three are used for their intended purposes, the results are transformational.
Agile and DevOps go hand in hand. Agile Development focuses on business agility by Dev Team collaborating with Business and creating potentially shippable increments of the Product. DevOps is aimed at collaboration between the Development Team and the Operations team to produce working production increments.
DevOps & CI/CD
DevOps & CI/CD are used interchangeably. However, DevOps is typically focused on culture and roles that emphasizes collaboration and communication, while CI/CD (which stands for Continuous Integration/Continuous Delivery) is focused on tools for product lifecycle management and emphasizes automation.
Now let me talk about CI and CD.
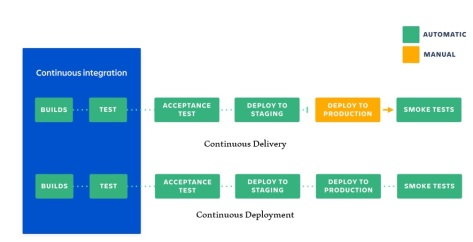
Figure: Continuous Integration, Delivery, Deployment
Developers practicing continuous integration merge their changes back to the main branch as often as possible. These software changes are validated by creating a build and running automated tests against the build. By doing so, you avoid code base instability that usually happens when people wait until it’s release time to merge their changes into the release branch. Continuous integration puts a great emphasis on testing automation to ensure that the application is not broken whenever new commits are integrated into the main branch.
Continuous delivery is an extension of continuous integration to make sure that you can release new changes to your customers quickly in a sustainable way. This means that on top of having automated your testing, you also automate your release process and you can deploy your application at any point through manual click of a button, at any desired frequency, be it daily, weekly, or whatever suits your business requirements. To reap the benefits of Continuous Delivery, you should deploy to production as early as possible to release small batches for easy validation and troubleshooting.
Continuous deployment goes one step further than continuous delivery. With this practice, every change that passes all stages of your production pipeline is released to your customers and developers can see their work go live within minutes. There’s no human intervention, and only a failed test will prevent a new change from being deployed to production. This accelerates the feedback loop with your customers and takes pressure off the team as there is neither a release day nor a maintenance window outside working hours to push software changes.
DevOps – Culture change
The first and foremost step in a DevOps adoption journey is being cognizant of the cultural change involved. Below are some essential changes to bring about for a successful transition.
- Dynamic cross-functional team focused on delivering business success where everyone is empowered and accountable.
- Commitment to a blameless culture that responds to experimentation and organizational learning, while eliminating fear of failure.
- Close alignment between IT and business leadership, with common vision and goals shared by CIO, VP of Apps and business leaders.
- Generative high trust and collaborative culture that is driven top-down.
In the older Ops model, developers are constantly seeking to create new code and respond to changing needs, while operations is focused on maintaining stability and reliability. In contrast to this, high-performing DevOps teams have a common goal – the goal of making quality, availability, and security everyone’s job, every day. Instead of throwing code over the proverbial wall to the IT operations team, the entire application development and update process is much more collaborative.
The empowerment of individuals is key to culture change. The ability for people to make decisions without feeling their job is on the line is key, even if the decision turns out to be wrong. Accountability is paramount. Without establishing a core ethos of shared responsibility, any DevOps initiative is bound to fail from the start. In order to cultivate a thriving DevOps culture, developers need to be both empowered and obligated to take ownership and responsibility for any issues caused in production. And you want this alignment to reflect top-down, starting with CIO, VP of Apps and any other relevant LOB leaders.
It’s really important to communicate without playing the blame game by shifting the mindset for people to focus mainly on the work being done rather than the people behind the work. DevOps is about experimentation. Experiments will often fail, but each experiment is another learning point for the organization.
Generative high trust organizations actively seek and share information to better enable the organization to achieve its mission. Responsibilities are shared and failure results in reflection and genuine inquiry within such organizations.
Change, especially cultural change, doesn’t happen without top-down sponsorship and is most effective when top down rather than bottom up.
Sample DevOps Maturity Model
If you think that you’re up for a cultural change, perform DevOps maturity assessment to identify the right set of processes and tools, based on the project and team. Repeat the assessment periodically to measure progress and update processes to evolve to the next stage.
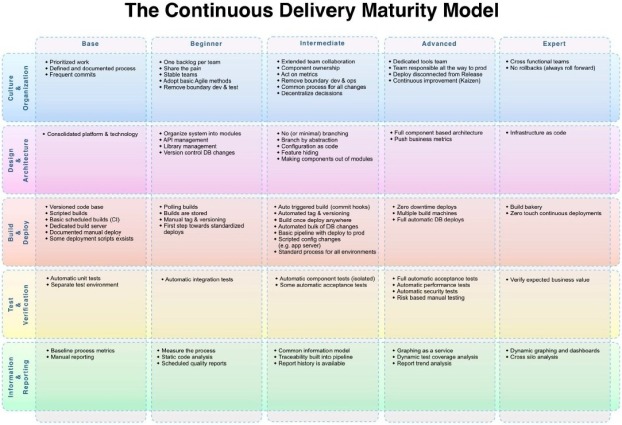
Source: https://www.infoq.com/articles/Continuous-Delivery-Maturity-Model
DevOps – No two journeys are the same
DevOps journeys differ across enterprises and across specific teams within a given organization based on their current maturity level, pain points and critical need of specific applications within the organization and market dynamics.
Digital transformation programs require alignment and collaboration between CIO, Chief Digital Officers and many other C-suite leaders. However, the executive sponsor and his/her functional alignment to IT vs. LOBs could heavily influence whether a particular enterprise starts its DevOps journey in Agile development, microservices architecture, implementation of CI/CD pipelines or extending beyond infrastructure automation into Infrastructure as Code (IaC). Organizations tend to derive benefits along their DevOps journey, irrespective of whether they adopt Agile development and CI/CD implementation for an existing app, resort to architectural modernization and use of microservices as part of their cloud-native journey, or automate their infrastructure delivery and package applications as containers to improve operational efficiency and infrastructure utilization.
Aligning Cloud & DevOps adoption
One of the core tenets of DevOps is the application of automation to streamline processes for increased IT operations and developer productivity. For organizations that adopt DevOps prior to moving to the cloud, teams can automate server configuration and code with tools like Ansible or Chef. However, hardware elements are much harder to automate since legacy equipment does not offer ready-to-use APIs. In contrast, cloud computing offers the ability to automate provisioning of not just software but also infrastructure elements (e.g., routers and load balancers). Through code and templates, teams can automatically summon elements as diverse as security services, databases and networking.
Concurrent adoption of DevOps and Cloud is the most efficient and gets you to DevOps faster. It allows an organization to adopt automation at all levels concurrently, using technology to enforce new DevOps processes while maximizing efficiencies.
A Winning DevOps approach – PACE Layered
While Cloud-native helps make fundamental transformation within an organization, not all existing applications within an organization need to get on to a DevOps pipeline.
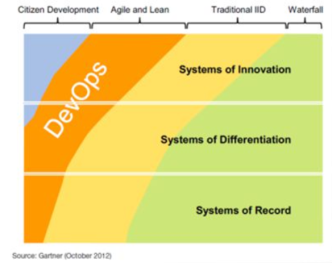
I would suggest that you categorize applications based on Gartner’s PACE layered application strategy, with pace denoting how fast any application changes. The three application layers are –
- Systems of Record – These are typically third-party application software with some customization for the specific organization, and support administrative and transaction processing activities, such as finance, HR, asset management, or procurement and thereby change with the least frequency.
- Systems of Differentiation – These applications support processes unique to the organization or its industry. These are innovations that have matured and are going through incremental changes and change at a mediocre pace of once in every few quarters.
- Systems of Innovation – This category includes applications built to support new, innovative business activities and are constructed quickly to enable enterprises to take advantage of these new ideas and opportunities in the market. These are ideally released on an ongoing basis to validate business ideas or fail fast based on learnings from customer feedback.
For best results when introducing DevOps to your IT organization, identify new applications designed for change that have a higher tolerance of risk.
The core usecase of DevOps is in Agile development, though it can be applied broadly to other categories such as Iterative and Incremental Development (IID) and Citizen development (low code app development) to benefit from improved collaboration and extensive automation.
DevOps: Where and how to start?
The previous step helps us identify the category of applications to choose from. Next, let me provide some guidance on the specific type of application to pick and how to kickstart implementation.
Start small and iterate with a project which is straightforward and not mission-critical, to find the right balance for your business. Early iterations with a new Agile-DevOps Product team might take time to improve velocity. Keep team sizes small and encourage scope of each team’s domain to be small and bounded. Start with one Agile-DevOps team and then move to several teams creating an application via Scrum of Scrums.
Some organizations focus on Agile-DevOps team dynamics and tackling a project. IT groups tend to focus on automation. Assess knowledge base and expertise of your team, operational readiness and experiment with different tools.
To reiterate, my learning has been that organizations which started their journey to address their biggest pain point and most critical tactical need, factoring in their industry drivers and constraints, were the most successful with DevOps implementation.
Organizing Teams for DevOps
Now that we’ve identified where to start with DevOps, let us ensure our teams are organized well to support these initiatives.
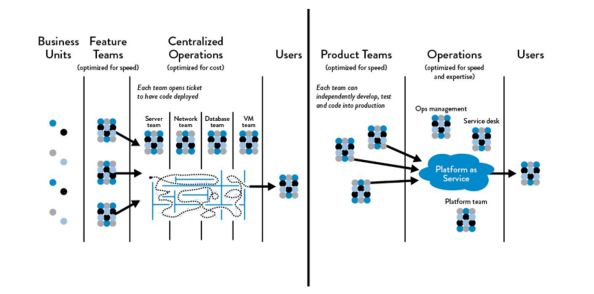
Source: Functional vs. Market Orientation Work: The DevOps Handbook, Kim et al.
To better achieve DevOps outcomes, we need to reduce the effects of functional orientation which is optimized for cost and expert skill development, and instead enable market orientation which is optimized for speed and quickly delivering value to the customer by having many small teams working independently. These market-oriented teams are responsible not only for feature development but handle idea conception through retirement as they’re cross-functional and independent. They are able to design and run user experiments, build and deliver new features, deploy and run their service in production, and fix any defects without dependencies on other teams, thus enabling them to move faster.
I’m not suggesting that you do a large, top-down reorganization to achieve market orientation as it could potentially create fear and paralysis, and impede progress. Instead, you could plan to embed functional skills such as QA, Ops, and Infosec into each product team, or alternately provide their capabilities to these teams through automated self-service platforms that provide production-like environments, initiate automated tests, or perform deployments. This would help you move away from a model where the product team has to wait on open tickets to groups such as IT Operations or InfoSec. This model has been touted by Amazon as one of the primary reasons behind their ability to move fast even as they grow.
While market oriented teams are highly recommended when teams are being built from the ground up, this isn’t the only way to achieve fast flow and reliability. It is possible to create effective, high-velocity organizations with functional orientation as long as everyone in the value stream are focused on organizational outcomes, regardless of the function within which they reside in the organization. Etsy, Google and GitHub are among those who’ve achieved success with functional orientation, given their high-trust culture that enables all departments to work together effectively.
DevOps – Roles & Skills
Next, let us delve deeper into the typical composition of various teams, and required skillsets to better enable DevOps adoption. I’ll also touch upon what you need to take into consideration when resourcing a team in a DevOps organization.
In organizations that have embraced DevOps, I’ve typically seen 3 different teams – Product, DevOps and IT Ops teams.
Product Team – Each product team owns a specific service and is designed to be cross-functional and independent. The core team usually consists of product owner, scrum master, developer, test engineer, SQA engineer, architect, DevOps, and InfoSec. Generalizing Specialists i.e. those with T-shaped (deep expertise in one area and broad skills across many areas) and E-shaped skills (deep expertise in a few areas and experience across many areas with proven execution skills and always innovating with limitless potential) would be better fits than “I” shaped skills (deep expertise in a specific area only) for the core product team. Be cognizant that developers have been agile for a longer time than operations, and many of the Ops teams have some catchup to do, when they’re pulled into an Agile product team.
IT Ops isn’t going away with DevOps. Instead we can expect to see IT Ops adopting SDLC best practices to automate infra delivery through IAC. Given the significant operational efficiency gains through DevOps, I’ve seen ops headcount shift to Dev to hire DevOps/Site Reliability engineers/cloud engineers.
DevOps Team – Within the industry, we tend to agree on the need for product teams. In contrast, there are some who’d vehemently argue against a separate DevOps team justifying that it goes against the vein of DevOps, which is guided by collaboration between Engineering and Ops. However, in practice, while there is Ops representation in product teams through DevOps participation in Agile ceremonies, there is a well-defined DevOps team in most organizations, with specific responsibilities outside of the product team to (a) help automate and streamline operations and processes (b) build and maintain tools for deployment, monitoring, and operations and (c) troubleshoot and resolve issues in dev, test and production environments.
Typically, IT Ops function is centralized, and DevOps teams are part of individual LOBs.
IT Ops – Value to & through DevOps
DevOps teams have every interest in working in partnership with IT Ops to ensure they have access to the resources they need to deliver services in a way that avoids bottlenecks or barriers to entry.
IT Ops continues to be valuable in a DevOps organization by
- Offering infrastructure services that DevOps can consume quickly and easily.
- Obtaining economies of scale by serving up shared infrastructure.
- Designing infrastructure per corporate governance requirements around business continuity, compliance and information security.
- Serving as the broker of physical, virtual and cloud resources.
IT Ops, in turn, derives value through DevOps by limiting shadow IT, and leveraging operational efficiency and productivity boosts that DevOps brings to the organization.
CI/CD – Implementing Pipelines
Automation of release tasks is a core requirement for DevOps teams. There are tools and technologies that support automation and collaboration between teams. The below diagram captures few sample tools for each DevOps phase.
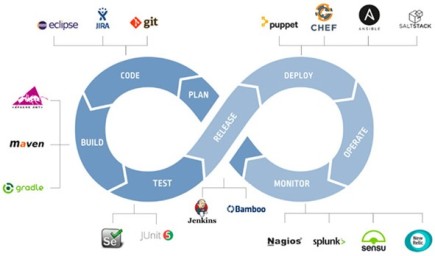
Source: https://www.helpnetsecurity.com/2019/01/18/protecting-privileged-access/
Think of building a continuous pipeline as creating a toolchain of loosely-coupled event driven providers and consumers to automatically move application code through these phases in the release process with zero latency. Multiple pipelines are typically built for a single application depending on the phases covered and the environment (staging, pre-prod, prod) to which the application code is released.
On selecting tools for implementing a pipeline for a given application, below are few criteria for identifying (a) relevant stages in your pipeline and (b) tools to use in each stage.
- Identify pain points and focus on tools for relevant stages.
- Evaluate tools based on ease of learning, implementation, out-of-box features, extensibility, applicability for your environment, marketplace and any other organizational requirements.
- Be wary of swapping one tool out for another due to lack of needed functionality and ensuing solution fragility and support costs.
- Leverage learnings from DevOps initiatives within other groups in your organization, and aim at shared tools but give ample space for individual teams to pick their tools.
Continuous Delivery is already highly adopted for Application Development, while databases have been left behind with only one-third adopting similar technologies and tools for their database environments.
DevOps Tools Landscape
I’ve included this infographic just to illustrate that Devops tools landscape is a crowded one. So don’t get into analysis/paralysis when choosing tools.

Source: harness.io
Limit your evaluation phase of tools for your specific environment and process. Given that DevOps is not a one-size-fits-all approach, I will not recommend any tools for each pipeline stage.
DevOps – Measuring progress
Executives, higher up in the management chain, often face the challenge of just hearing positive news which is not quantified, and negative updates being kept under wraps. The best countermeasures to this inaccurate communication are mutually reinforcing pillars of automation and measurement. Put together a DevOps dashboard to automate progress tracking. Make sure that your initial adoption plan includes putting together a DevOps dashboard. Use the dashboard to assess DevOps progress at regular cadence.
Low-level operational metrics won’t do the trick. The metrics you present to upper management must tie back to business value. They’re not interested in a bunch of numbers that show how much code you’re getting out the door. They want to know how quickly you got something with quantifiable value to market.
To help with this, DevOps teams adopt digital experience monitoring and analytics solutions that correlate data — from the point of customer engagement to back-end business processes.
The last 3 slides starting this one should sum up all that I’ve talked about so far.
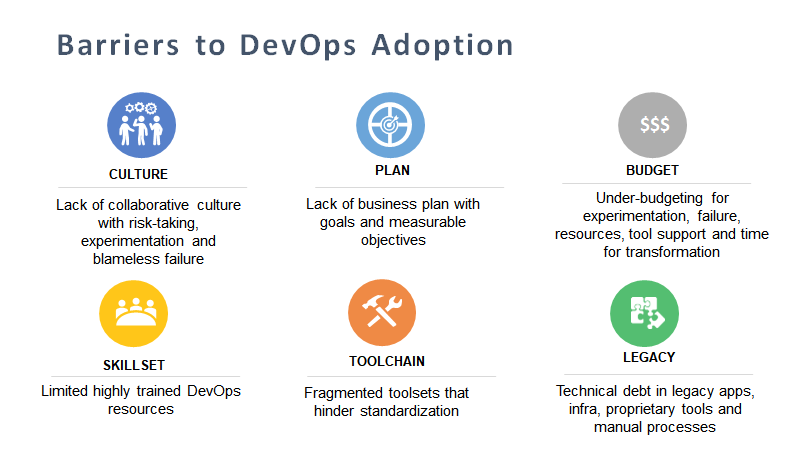
While DevOps has gone mainstream, barriers to DevOps still exist within organizations. Such barriers vary based on the type of organization, its size, existing processes and degree of deployment scale among other aspects.
Culture: DevOps initiatives require a collaborative culture, with risk-taking, experimentation and failure forgiveness baked in. Usually, culture is the hardest to change and has been rated as the #1 barrier to DevOps. A business-as-usual attitude may not work. To overcome this barrier, it is critical for enterprises to make conscious efforts to embrace a shift in culture during DevOps rollout, through executive sponsorship, election of champions and adoption of collaborative tools (such as Slack) for a top-down and bottom-up culture shift to happen.
Plan – In organizations that have spun up DevOps projects as bottom-up initiatives, organizational resources such as program managers, planning processes, budget allocation and executive buy-in were sporadic and projects were not specifically tied to business goals or measurable objectives resulting in limited success that could not build momentum. This barrier can be overcome through structured planning and securing executive sponsorship for DevOps initiatives.
Toolchain – Fragmented toolsets including multiple open-source tools have hindered standardization and slowed down adoption. This problem is likely to continue for several years until the toolchain ecosystem consolidates further and DevOps governance is mainstreamed and standardized across corporate systems including IT, LoB, partners, etc.
Budget/Skillset – Most DevOps projects have under-budgeted for experimentation, failure, resources, tool support and time for transformation. However, enterprise-grade support fees for open source tools, non-standardized tool adoption and expensive DevOps resources skewed budget. Being informed of this propensity should help enterprises overcome this barrier.
Legacy: Brownfield deployments with legacy infrastructure induce complexity for cloud models. Infrastructure rigidity and access to physical environments induce delays. Organizations that have on-premise infrastructure, proprietary tools and manual processes all suffer from legacy technical debt. A number of tools now straddling brownfield and greenfield deployments are sprouting up which should help ease this barrier.

Here are the best practices I’d recommend for better DevOps success.
- Tailor your implementation to address pain points in your release process.
- Take stock of where you are for the given application under consideration before charging ahead with implementation.
- Encourage experimentation using pilot initiatives to create some quick wins, and also identify the right balance for the specific team that is now implementing DevOps, while still leveraging DevOps learnings from within the wider organization.
- It is highly critical to invest in building an internal DevOps community in the organization so that they can help understand what other teams are working on and there is cross-pollination of best outcomes and toolsets.
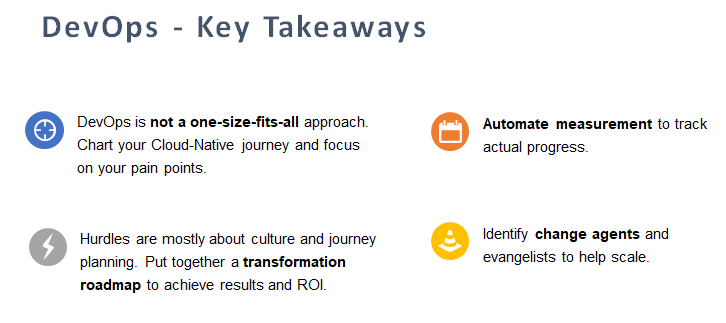
Here is a quick explanation of key takeways from my talk.
- DevOps is not a one-size-fits-all approach but needs to tailored to address specific pain points, within the context of the overall Cloud-Native journey.
- The most commonly cited challenge with DevOps is in making cultural change happen and lack of a guiding transformation roadmap to drive measurable business outcomes.
- Automate measurement through DevOps dashboard to track actual progress based on business impact.
- Change agents who help with OCM (Organizational change management) are key to instilling and coaching Agile, Collaboration and Automation mindset and helping operationalize it on a daily basis.

Finally, remember that DevOps is about culture and collaboration, rather than tools for automation.
PwC’s global strategy consulting business found that companies facing disruption generally have longer to respond than they expect, and an effective response is typically available to them. It was earlier unthinkable that any Enterprise could transform itself fundamentally as we currently witness today in the Cloud-Native era. There is always hope to save your organization from the brink of extinction and become a powerhouse competitor by reinventing through Cloud-Native practices.